南京大学团队在软件过程制品可追踪性方面的研究取得突破性进展,最新研究成果被软件工程学科国际顶级会议ESEC/FSE2022(CCF-A 类)录用,论文标题为”Semi-Supervised Pre-processing for Learning-based Traceability Framework on Real-World Software Projects”。
通过对业界真实软件项目过程数据的调研发现开发过程中软件制品的质量问题堪忧,其中可追踪性尤为严重。本文工作深入研究了基于半监督学习框架(semi-supervised learning)在可追踪性还原任务上的实践效果;目前基于学习式的自动化可追踪性模型往往面临着两个典型(关键)的挑战,即数据不平衡(data imbalance)和数据稀疏(data sparsity)问题。为了克服这些挑战,本文提出了SPLINT框架,创新性地通过整合混合文本相似性特征及半监督学习策略,有效缓解了样本特征空间稀疏性问题,半监督学习可以用来在标记样本稀疏的情况下用未标记样本来增强训练集。
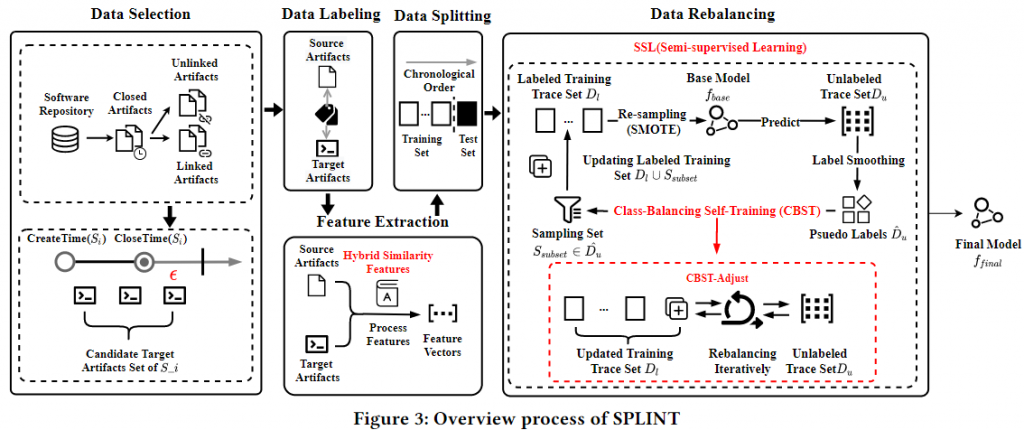
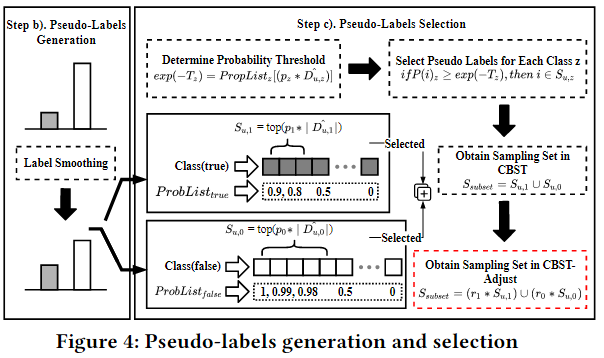
同时,该论文重点针对样本类别不平衡情况,引入了基于样本比例的类平衡-自我训练样本选择策略(adjusted class-balancing and self-training selection strategies, CBST-adjust), 由此半监督学习过程中选择的样本遵循向少数类添加较多的样本且向多数类添加较少的样本的规则来重新平衡训练集。
通过在6个开源项目和10个工业界项目数据上的实验结果显示,SPLINT相较于传统可追溯性IR恢复模型及baseline ML-based 可追溯性分类模型获得了显著更优的效果。且由于工业界项目因数据不平衡和稀疏性问题更加严重,其F2-score,AUC平均值分别达到14%和8%的效果提升。
该研究工作获得了国家自然科学基金、国家重点研发计划、江苏省重点研发计划等基金的支持。